在 Go 语言中,我们可以为 Go 程序编写三类测试:功能测试(test)、基准测试(benchmark,也称性能测试)以及示例测试(example)。前两类测试见名知意,而示例测试严格来讲也是一种功能测试,只不过它更关注程序打印出来的内容(相较于,在什么情况下因什么样的输入应该产生什么样的输出)。
一般情况下,一个测试源码文件只会针对某个命令源码文件,或库源码文件做测试,所以我们总会(并且应该)把它们放在同一个代码包内。测试源码文件的主名称应该以被测源码文件的主名称为前导,并且必须以“_test”为后缀(比如被测源码文件 demo.go 的测试源码文件名应该是 demo_test.go)。每个测试源码文件都必须至少包含一个测试函数,从语法上讲,每个测试源码文件中都可以包含用来做任何一类测试的测试函数,即使把这三类测试函数都塞进去也没有问题(只要把控好测试函数的分组和数量就行)。
Go 语言内置了一套单元测试和性能测试系统,仅需添加很少的代码就可以快速测试一段需求代码。
go test命令
go test命令会自动读取源码目录下面名为 *_test.go 的文件,生成并运行测试用的可执行文件。
1 | go test [...] |
go test命令会先做一些准备工作,比如确定内部需要用到的命令、检查我们指定的代码包或源码文件的有效性、以及判断我们给予的标记是否合法等等。在准备工作顺利完成之后,go test命令会针对每个被测代码包依次地进行构建、执行包中符合要求的测试函数,清理临时文件,打印测试结果。
为了加快测试速度,Go 语言通常会并发地对多个被测代码包进行功能测试,只是在最后打印测试结果的时候,它会依照我们给定的顺序逐个进行,给人一种完全串行执行的错觉。另一方面,由于并发的测试会让性能测试的结果存在偏差,所以性能测试一般都是串行进行的。更具体地说,只有在所有构建步骤都做完之后,go test命令才会真正地开始进行性能测试,并且下一个代码包性能测试的开始,总会等到上一个代码包性能测试的结果打印完成后。
(内置)单元测试框架
Go 语言规定功能测试函数的名称必须以Test为前缀,并且参数列表中只应有一个*testing.T类型的参数声明。
1 | func TestXxx( t *testing.T ){ |
Go 语言要求示例测试函数的名称必须以Example为前缀,但对函数的参数列表没有强制规定。
(内置)性能测试框架
Go 语言同样规定性能测试函数的名称必须以Benchmark为前缀,并且唯一参数的类型必须是*testing.B类型。
1 | func BenchmarkXXX( b *testing.B ){ |
b.N 表示这个用例需运行的次数,数值视情况而定。go test命令会先尝试把 b.N 设置为1,如果测试函数的执行时间没有超过上限(默认 1s,使用-benchtime参数可修改时间上限),命令就会改大b.N的值,然后再次执行测试函数,如此往复,直到这个时间大于或等于上限为止。
默认情况下,go test命令不会执行Benchmark测试,必须用“-bench go test命令的时候不加-run标记,那么就会使它执行被测代码包中的所有功能测试函数。
1 | //只需执行puzzlers/article20/q3目录下所有Benchmark测试 |
“BenchmarkGetPrimes-8” 表示执行性能测试函数时所用的最大 P 数量为 8,go test命令中加入标记-cpu可以设置一个最大 P 数量的列表,以供命令在多次测试时使用。
性能测试受环境的影响很大,为了保证测试的可重复性,在进行测性能测试时时,尽可能地保持测试环境的稳定。比如机器处于闲置状态、毋共享硬件资源,机器是否关闭了节能模式,避免使用虚拟机和云主机进行测试。
性能分析(profiling)工具
基准测试(Benchmark)可以度量某个函数或方法的性能,也就是说,如果我们知道性能的瓶颈点在哪里,benchmark是一个非常好的方式。但是面对一个未知的程序,如何去分析这个程序的性能(CPU Profiling、Memory Profiling、Block Profiling、Mutex Profiling——与Blocking Profiling类似,但专注于因为锁竞争导致的等待或延时),并找到瓶颈点呢?
Go 内置的生态提供了大量的 API 及工具用于诊断程序的逻辑及性能问题,最常用的当属 pprof 工具。
pprof 以profile.proto 读取分析样本的集合,并生成报告以可视化并帮助分析数据(支持文本和图形报告),它有两种“使用姿势”:
runtime/pprof:采集程序(非 Server)的运行数据(调用pprof.StartCPUProfile/pprof.StopCPUProfile等API)进行分析;net/http/pprof(对runtime/pprof进行了封装并在http端口上暴露出来):采集 HTTP Server 的运行数据进行分析;
通过手动调用runtime/pprof以文件方式输出Profileruntime/pprof的API,我们可以对特定代码段进行分析,灵活性较高,适用于工具型应用(比如说定制化的分析小工具、集成到公司监控系统)。
使用过程简单示例如下:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70package main
import (
"log"
"os"
"runtime/pprof"
)
const (
row = 1000
col = 2000
)
func fillMatrix(m *[row][col]int) {
s := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < row; i++{
for j := 0; j < col; j++{
m[i][j] = s.Intn(100000)
}
}
}
//代码释义,无实质含义
func calculate(m *[row][col]int) {
for i := 0; i < row; i++{
tmp := 0
for j := 0; j < col; j++{
tmp += m[i][j]
}
}
}
func main() {
//创建 CPU profile 文件
cpuFile, err := os.Create("cpu.prof")
if err != nil {
log.Fatal("could not create CPU profile:", err)
}
if err := pprof.StartCPUProfile(cpuFile); err != nil{
log.Fatal("could not start CPU profile:", err)
}
defer pprof.StopCPUProfile()
//主逻辑区,功能实现... ...
x := [row][col]int{}
fillMatrix(&x)
calculate(&x)
memFile, err := os.Create("mem.prof")
if err != nil {
log.Fatal("could not create memory profile:", err)
}
//runtime.GC()
if err := pprof.WriteHeapProfile(memFile); err != nil {
log.Fatal("could not write memory profile:", err)
}
memFile.Close()
groutFile, err := os.Create("goroutine.prof")
if err != nil{
log.Fatal("could not create goroutine profile:", err)
}
if gProf := pprof.Lookup("goroutine"); gProf == nil{
log.Fatal("could not write goroutine profile")
}else{
gProf.WriteTo(groutFile, 0)
}
groutFile.Close()
}
编译并执行该源码文件,在当前目录下会生成cpu.prof、mem.prof和goroutine.prof 三个概要(profile)文件。
使用go tool pprof [binary] [binaryCertain.prof]命令可以分析指定的概要文件并使得我们能够以交互式的方式访问其中的信息,这里以 CPU性能分析 cpu.prof文件为例:
1 | $ go tool pprof main cpu.prof |
(pprof) help可以查看它所有支持的命令和选项。
除了在命令行中使用交互模式查看分析数据外,我们还可以在网页中查看:
1 | $ go tool pprof -http=:9999 cpu.prof |
访问 localhost:9999就可以看到如下页面,便于直观地进行数据分析。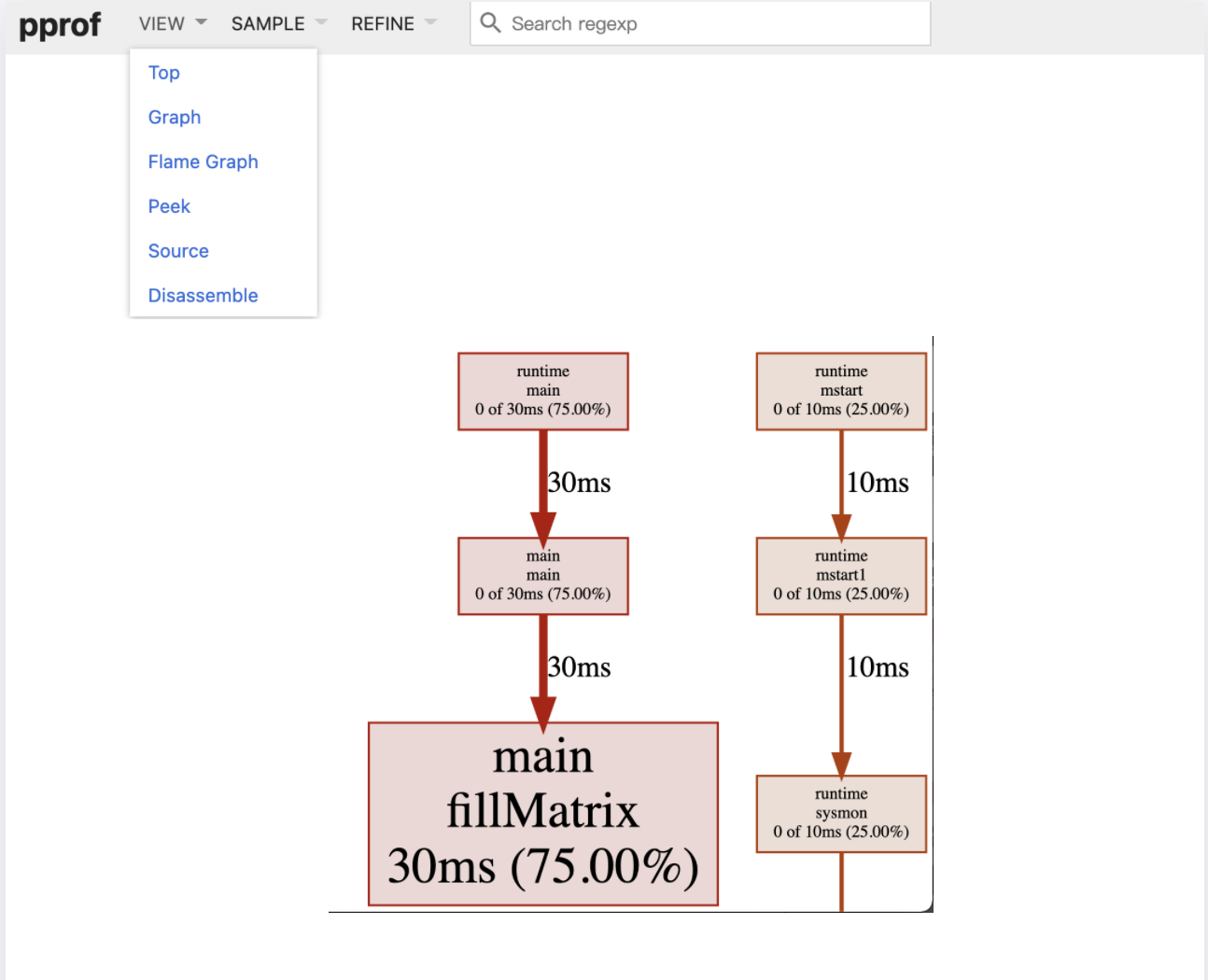
net/http/pprof以 HTTP 方式输出 Profile
通过在应用程序中导入import _ "net/http/pprof"并启动http server(应用程序本就是http server时就不必了)来获取性能数据(profile),引入方式简单,适合于持续性运行的应用(比如在线服务)。
1 | import _ "net/http/pprof" |
使用过程示例(上例改造,限于释义)如下:
1 | package main |
编译并执行该源码文件(启动HTTP服务),浏览器访问 http://127.0.0.1:8085/debug/pprof就可以如下索引页面,点击链接即可进入子页面查看对应的性能数据。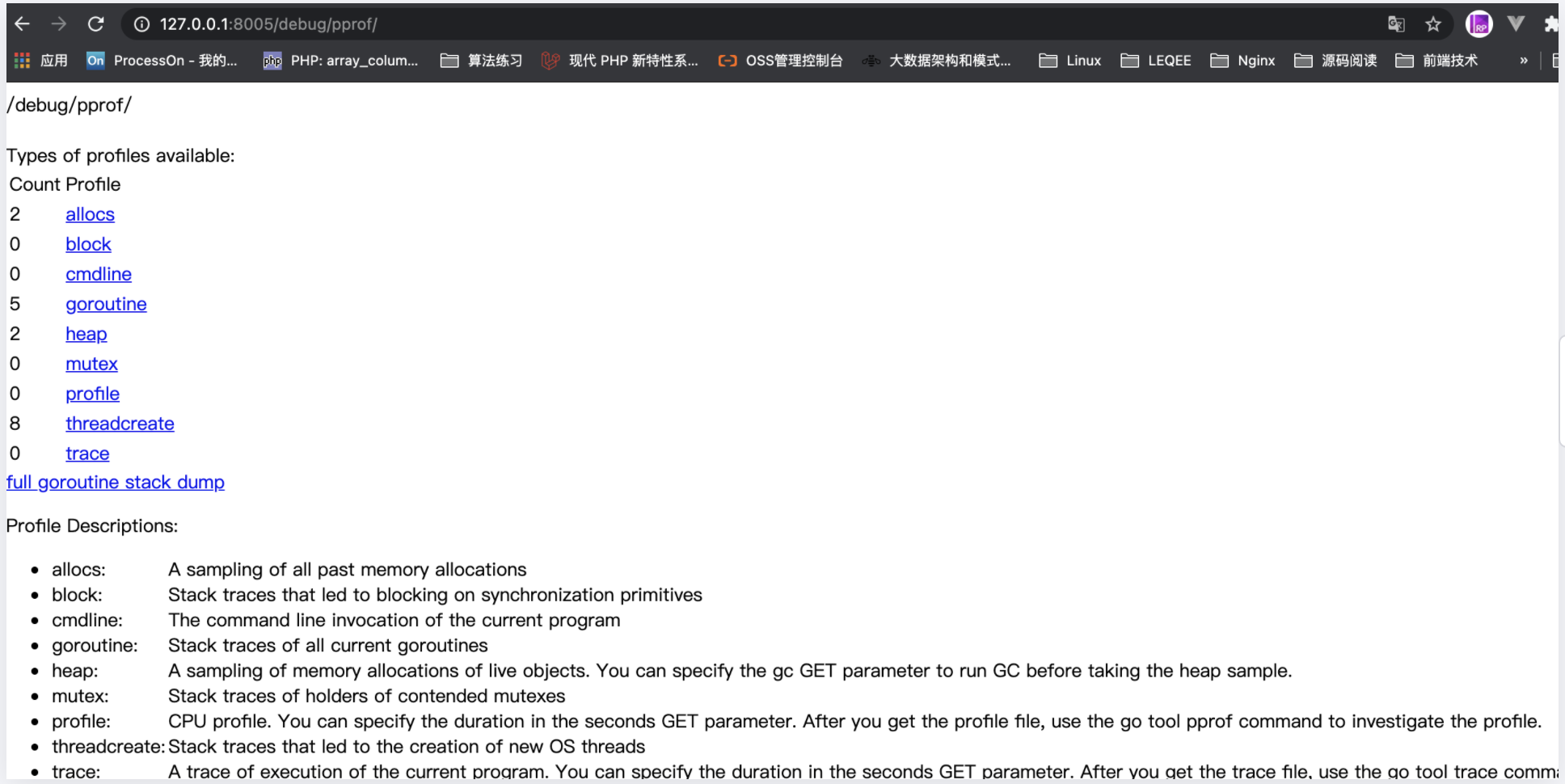
- profile(CPU Profiling): 默认进行 30s 的 CPU Profiling 并导出文件,可由GET参数seconds=10指定采样时间;
- block(Block Profiling): 查看导致阻塞的 goroutine 堆栈(如 channel, mutex等)【
runtime.SetBlockProfileRate】; - goroutine : 查看当前所有运行的 goroutines 堆栈信息;
- heap(Memory Profiling): 查看活动对象的内存分配情况,采样前可由GET参数 gc 触发
runtime.GC; - mutex(Mutex Profiling): 查看导致 mutex 竞争的 goroutine 堆栈【
runtime.SetMutexProfileFractio】; - threadcreate : 查看导致创建 OS 线程的 goroutine 堆栈;
1
2
3
4
5
6$ go tool pprof http://127.0.0.1:8085/debug/pprof/profile
Fetching profile over HTTP from http://127.0.0.1:8005/debug/pprof/profile //采样用户请求数据
Saved profile in /Users/hannah/pprof/pprof.samples.cpu.001.pb.gz
Type: cpu
... ...
(pprof) //默认进入 pprof 的交互式命令模式
通常情况下,我们会先使用
runtime/pprof或net/http/pprof对应用进行整体分析,找到性能瓶颈点后再使用go test -bench=. [-cpuprofile=$FILE] [-memprofile=$FILE -memprofilerate=N] [-blockprofile=$FILE]命令进一步确定热点加以优化并对比测试。

