前言
HTTP报文是HTTP应用程序之间发送的数据块(搬东西的包裹)。这些数据块以文本形式元信息(meta-information)开
头,这些信息描述了报文的内容及含义,后面跟着可选的数据部分。这些报文在客户端、服务器和代理之间流动。
报文的组成部分
HTTP报文是简单的格式化数据块,每条报文都包含一条来自客户端的请求(请求报文),或者一条来自服务器的响应(响
应报文)。它们由三部分组成:对报文进行描述的起始行(start line)、包含属性的首部块(header),以及可选的、包含数据的主体(body) 部分。
1 | 请求报文格式: |
如下实例图示,起始行和首部就是由行分割的ASCII文本,每行都以由两个字符组成的行终止序列(CRLF)作为结束,其中
包含一个回车符(ASCII 13)和一个换行符(ASCII 10)。尽管HTTP规范中说明应该用CRLF来表示终止,但稳健的应用
程序也应该接受单个换行符作为行的终止(有些老的或者不完整的HTTP应用程序)。
报文的主体是一个可选的数据块,与起始行和首部不同的是,主体中可以包含文本或二进制数据,也可以为空。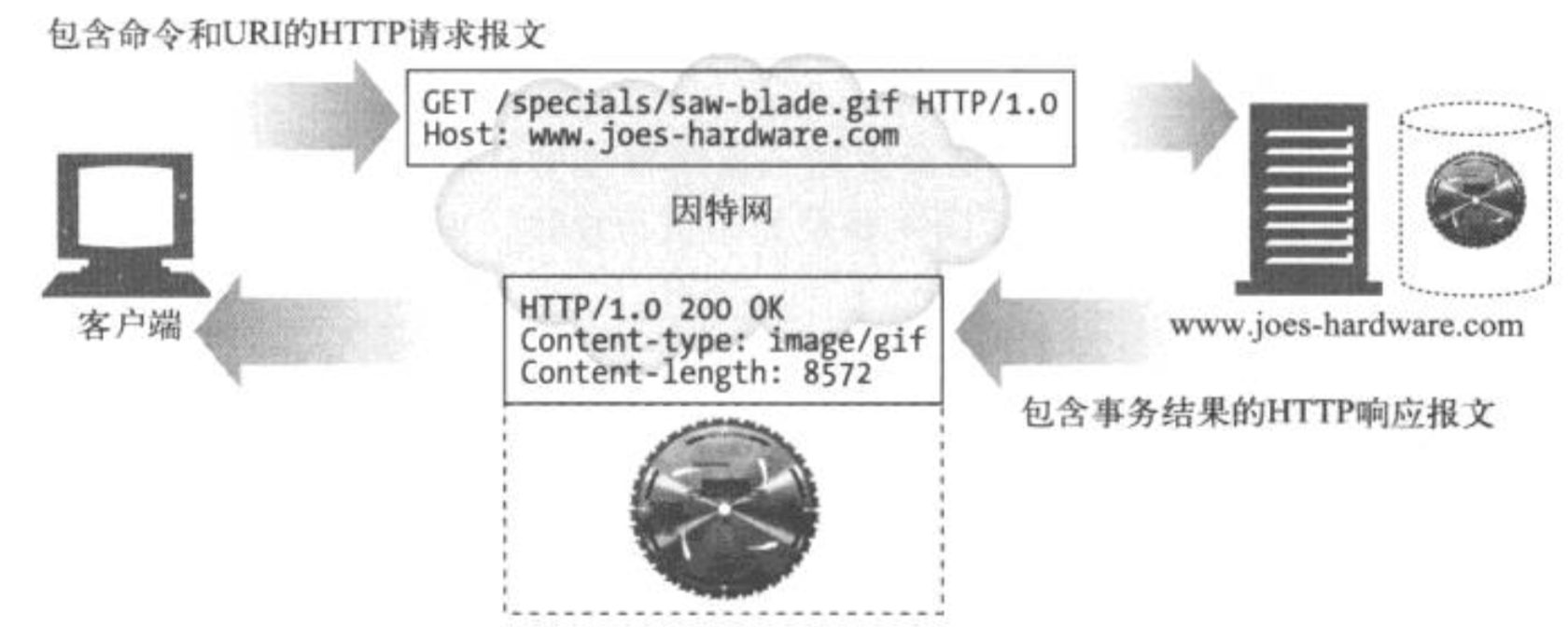
起始行
所有HTTP报文都以一个起始行作为开始,请求报文的起始行说明了要做些什么,响应报文的起始行说明发生了什么。
请求行
请求报文的起始行,包含了一个请求方法,一个请求URL和HTTP版本。请求方法(method)描述了客户端希望服务器对
资源执行的动作,比如GET、HEAD或POST;请求URL(request-url)描述了所请求资源,或者URL路径组件的完整
URL;HTTP版本(version)告知服务器客户端使用了哪种HTTP,HTTP/<major>.<minor>;所有这些字段都由空格符分隔。
响应行
响应报文的起始行,包含了响应报文使用的HTTP版本,数字状态码(status-code)和原因短语(reason-phrase)。状
态码这三位数字描述了请求过程中发生的情况,每个状态码的第一位数字用于描述状态的一般类别(成功、出错等);
原因短语,数字状态码的可读版本,包含行终止序列之前的所有文本;所有这些字段都由空格符进行分隔,在HTTP/1.0之
前,并不要求在响应中包含响应行。
方法
HTTP规范定义了一组常用的请求方法,下表描述了七种这样的方法,有些方法的请求报文中有主体,有些则是无主体的请求:
| 方法 | 描述 | 是否包含主体 |
|---|---|---|
| GET | 从服务器获取一份文档 | 否 |
| HEAD | 只从服务器获取文档的首部 | 否 |
| POST | 向服务器发送需要处理的数据部 | 是 |
| PUT | 将请求的主体部分存储在服务器上 | 是 |
| TRACE | 对可能经过代理服务器传送到服务器上去的报文进行跟踪 | 否 |
| OPTIONS | 决定可以在服务器上执行哪些方法 | 否 |
| DELETE | 服务器上删除一份文档 | 否 |
并不是所有服务器都实现了上表列出的七种方法(如果一台服务器要与HTTP 1.1兼容,只要为其资源实现GET和HEAD方
法就可以),而且由于HTTP设计的易于扩展,其他服务器上可能还会实现一些自己的请求方法(扩展方法)。
- GET,最常用方法,通常用于请求服务器发送某个资源。HTTP/1.1要求服务器实现此方法;
- HEAD,与GET方法行为非常类似,但服务器在响应中只返回首部,不用返回实体的主体部分,这允许客户在未获取实际资源的
情况下,对首部进行检查。服务器开发者必须保证返回的首部与GET请求返回的首部完全相同; - PUT,写入服务器文档,让服务器用请求的主体部分来创建一个由所请求的URL命名的新文档,或者如果URL已经存在的话,就用
这个主体来替代它(很多Web服务器要求在执行PUT之前用密码登录); - TRACE,客户端发起的请求可能要穿过防火墙,代理,网关等其他一些应用程序,每个中间结点都可以修改原始的HTTP请求。TRACE
会在目的服务器端发起一个”环回”诊断。行程最后一站的服务器会弹回一条TRACE响应,并在响应主体中携带他收到的原始请求报文,
这样客户端可检查请求/响应链上原始报文如何被毁坏或修改过(TRACE请求不能带有实体的主体部分);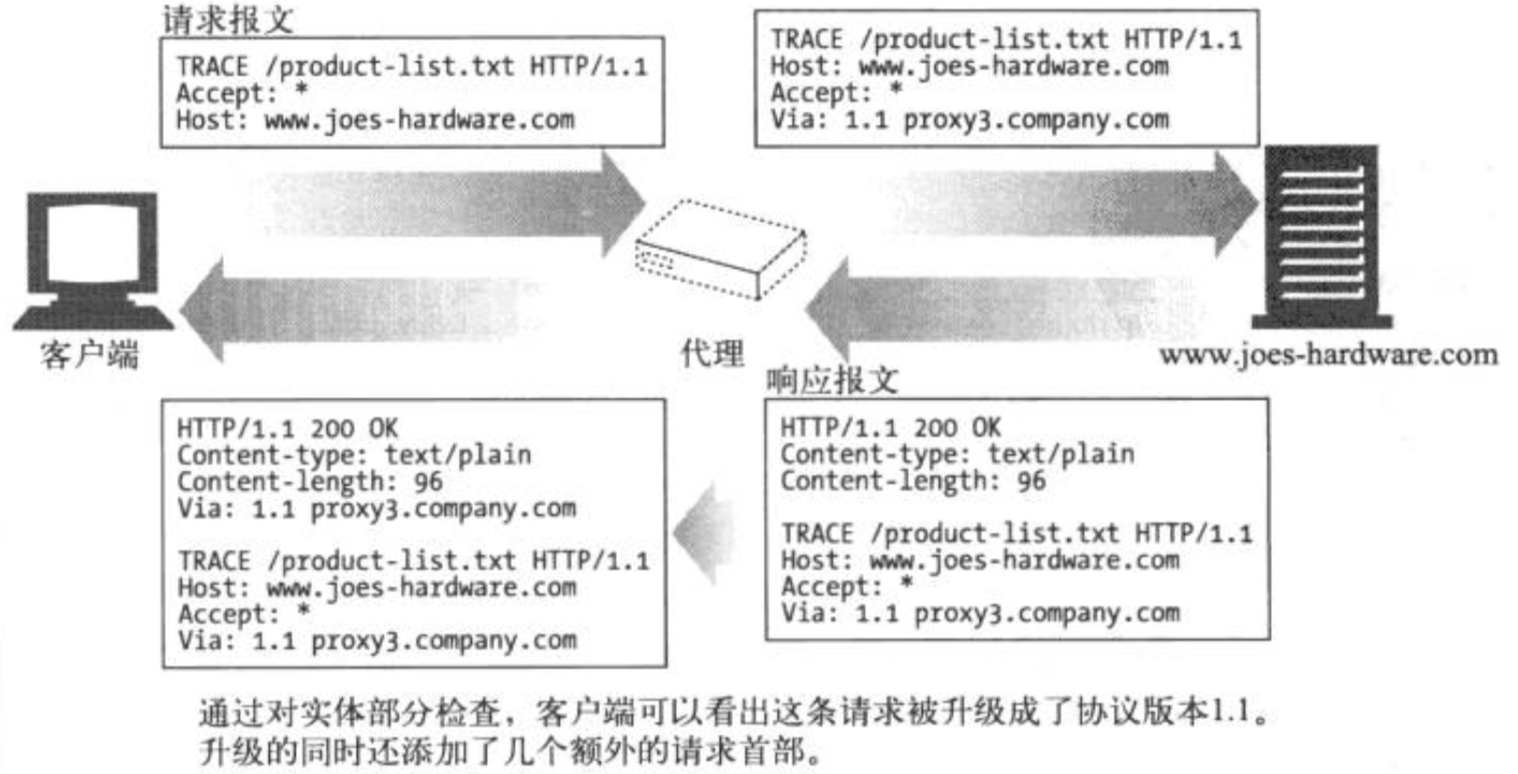
- OPTIONS,请求Web服务器告知其支持的各种功能,主要用途有两个:
- 获取服务器支持的HTTP请求方法,OPTIONS * HTTP/1.1;
- 用于检查服务器的性能,比如ajax进行跨域请求(客户端使用XmlHttpRequest发起ajax请求,多数主流浏览器均提供了对跨域
资源共享的支持;服务器端配置允许资源跨域访问:Access-Control-Allow-Origin,Access-Control-Allow-Headers,
Access-Control-Allow-Methods;)时的预检请求,用于判断实际发送的请求是否安全;
预检请求(Preflighted Request)是CORS中一种透明服务器验证机制,下面这两种情况需要进行预检,即非简单请求:
-请求方法不是GET,POST or HEAD,或者请求方法是POST但Content-Type不是application/x-www-form-urlencoded,
multipart/form-data,text/plain,比如application/xml or text/xml;
-设置自定义头,比如X-JSON,X-MENGXIANHUI;
- 某些扩展方法:LOCK,MKCOL,COPY,MOVE;“对所发送的内容要求严一点,对所接受的内容宽容一些”来处理扩展方法
状态码
方法用来告诉服务器做什么事情的,状态码则是用来告诉客户端发生了什么事情,比如HTTP/1.1 200 OK。可以通过三位数字码
对不同状态码进行分类,当前的HTTP版本只为每个状态定义了几个代码,随着协议发展,HTTP规范中会正式的定义更多状态码。
| 整体范围 | 已定义范围 | 分类 |
|---|---|---|
| 100~199 | 100~101 | 信息提示 |
| 200~299 | 200~206 | 成功 |
| 300~399 | 300~305 | 重定向 |
| 400~499 | 400~415 | 客户端错误 |
| 500~599 | 500~505 | 服务器错误 |
常用的信息性状态码及原因短语:
- 200,OK,请求没问题,实体主体部分包含了所请求的资源;
- 301,Moved Permanently,请求的URL已被移除,响应的Location首部中应该包含资源现在所处的URL;
- 302,Found,与301类似,但客户端应该使用Location首部给出的URL来临时定位资源;
- 400,Bad Request,告知客户端它发送了一个错误的请求;
- 401,Unauthorized,与适当首部一同返回,在这些首部中请求客户端在获取对资源的访问权前对自己进行认证;
- 403,Forbidden,请求被服务器拒绝,通常是服务器在不想说明拒绝原因时使用;
- 404,Not Found,说明服务器无法找到所请求的URL;
- 405,Method Not Allowed,发起的请求中带有所请求URL不支持的方法;
- 500,Internal Server Error,服务器遇到妨碍它为请求提供服务的错误;
- 501,Not Implemented,客户端发起的请求超出服务器能力范围,比如使用了服务器不支持的请求方法;
- 502,Bad Gateway,作为代理或网关使用的服务器从请求响应链的下一条链路上收到了一条伪响应;
- 504,Gateway Timeout,网关/代理在等待另一服务器对其请求进行响应时超时;
首部
跟在起始行后面的零个或多个首部,本质上讲,他们只是名/值对列表。每个首部都包含一个名字,后面跟着一个冒号(:),然后
可选的空格后接着字段值,最后是一个CRLF。一组HTTP首部总是应该以空行(单个CRLF)结束,表示了首部列表的结束和主体部
分的开始,即使没有首部和实体和主体的部分也应如此。但由于历史原因,很多服务器和客户端在没有实体的主体部分时,(错误
的)省略了最后的CRLF。
HTTP首部可以分为以下几类:通用首部,请求首部,响应首部,实体首部及扩展首部。
另注:将较长的首部分为多行可以提高可读性,多出来的每行前面至少要有一个空格或制表符(tab),比如:1
2
3
4
5HTTP/1.0 200 OK
Content-Type: image/gif
Content-Length: 8572
Server: Test Server
Version 1.0
通用首部
请求报文和响应报文都可以使用的首部,比如以下通用的信息性首部:Connection,Date,MIME-Version,Transfer-
Encoding,Update,Via,Trailer(报文采用分块传输编码时,此首部可列出报文拖挂(trailer)部分首部集合),Cache-
Control,Pragma;
其中关于Connection、Transfer-Encoding首部有一些值得一说的地方。Connection: keep-alive是HTTP1.0引入的,HTTP1.1成为默认值,这种持久连接能重用TCP连接,避免TCP慢启动、
消除连接及关闭时延。但有个问题,Keep-Alive模式下,客户端如何判断一次请求所得到的响应数据已经接受完成?
- 依据实体首部中的Content-Length字段,比如客户端请求一个静态页面或者一张图片;
- 然而多数情况下服务器不会预先知道响应实体的大小(Content-Length如果存在并且有效的话,则必须和消息内容的传输长度
完全一致),比如某些动态生成/查询的内容,此时若想获取实体准确长度就要开一个足够大的buffer,等内容全部生成好后再计算。
但这样一方面需要更大的内存开销另一方面也会让客户端等待很久;此时最理想的方式应是一边产生数据一边发送给客户端:Transfer-Encoding:chunked。
Chunked编码的数据格式如下示,分块编码由若干个Chunk串联而成,并由一个长度为0的chunk标示结束。每个Chunk分为头部和
正文两部分,头部指定该段正文的字符总数(十六进制)和数量单位(一般不写),两部分之间用CRLF隔开。最后一个Chunk长度
必须为0,表示部分实体结束。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16HTTP/1.1 200 OK
Content-Type: text/plain
Transfer-Encoding: chunked
25\r\n
\r\n
This is the data in the first chunk\r\n
1C\r\n
\r\n
and this is the second one\r\n
3\r\n
con\r\n
8\r\n
sequence\r\n
0\r\n
\r\n
那分块传输数据的完整性如何保证?由于Http工作在TCP/IP之上,依靠Chunked来保证数据完整性没有太大含义。
Chunked的意义在于Keep-Alive模式传输时,Chunked可以通过特殊处理(发送长度为0的chunk)表明该次的数据已经响应完毕了。
Content-Encoding和Transfer-Encoding二者经常结合来用,即针对内容压缩后再进行分块传输编码.
一般情况如果报文首部存在Transfer-Encoding就不必再使用Content-Length,但如果报文首部这2个头信息同时存
在,Content-Length也应该被忽略。
请求首部
只在请求报文中有意义的首部,用于说明谁在发送请求,请求源于何处或者客户端的喜好及能力,比如以下:
- 请求的信息性首部:
Client-IP,From(客户端用户的E-mail地址),Host,Referer,UA-color,UA-CPU,UA-Disp,UA-OS,UA-Pixels,User-Agent; - Accept首部:
Accept(客户端会发送的媒体类型),Accept-Charset,Accept-Encoding,Accept-Language,TE - 条件请求首部:为请求加上某些限制要求服务器对请求响应前,确保某个条件为真
Expect(客户端要求的服务器行为),If-Match(实体标记),If-Modified-Since,If-None-Match,If-Range,If-Unmodified-Since,Range; - 安全请求首部:
Authorization,Cookie,Cookie2; - 代理请求首部:
Max-Forward,Proxy-Authorization(同Authorization,与代理进行认证时使用),Proxy-Connection;响应首部
响应报文自己的响应首部集,用于说明谁在发送响应,响应者的功能,甚至与响应相关的一些特殊指令: - 响应的信息性首部:
Age(从最初创建始响应持续时间),Public,Retry-After,Server,Title,Warning(比原因短语更详细的警告报文) - 协商首部:
Accept-Ranges(对此资源而言服务器可接受的范围类型),Vary(服务器查看的其他首部列表) - 安全响应首部:
Proxy-Authenticate,Set-Cookie,Set-Cookie2,WWW-Authenticate;实体首部
提供了有关实体及其内容的大量信息,告知报文的接收者它在对什么进行处理: - 实体信息性首部:
Allow(列出可以对此实体执行的请求方法),Location(实体实际上位于何处); - 内容首部
Content-Base(基础URL),Content-Encoding,Content-Language,Content-Length,Content-Location,Content-MD5,
Content-Range(在整个资源中此实体表示的字节范围),Content-Type(主体的对象类型);
其中关于Content-Type首部在PHP的使用中值得一说的地方。
常见的Content-Type取值及其含义:application/x-www-form-urlencoded,浏览器原生form表单
(key1=val1&key2=val2),默认值,比如”Content-Type: application/x-www-form-urlencoded;charset=utf-8”;
multipart/form-data使用表单上传文件时form的encrypted等于此值,boundary分割开始,紧接内容描述信息,然后回
车最后是字段具体内容,不能从原始输入流echo file_get_contents(“php://input”);中获得;application/json,
消息主体是序列化后的JSON字符串,无法通过$_POST对象获取内容,可从php://input中获取;text/xml,比如XML-
RPC(XML Remote Procedure Call)就是将XML作为编码方式的远程调用规范。
Content-Encoding:gzip, deflate;
- 实体缓存首部:说明如何或什么时候进行缓存
Etag(与此实体相关的实体标记),Expires,
实体的主体部分
可选的实体主体是HTTP报文的负荷,即HTTP要传输的内容。HTTP报文可以承载很多类型的数字数据,比如图片,视频,电子邮件等。
报文首部信息的来源
对HTTP报文有了大体的了解后,除了人为编撰HTTP报文外,不禁有个疑问:一般情况使用的HTTP报文中的诸多Header信息是如何生成的呢?
我们以Agent代理为浏览器为例,HTTP请求报文有以下几部分协同生成:
- 浏览器自动生成的请求头,比如Host,Cookie,User-Agent,Accept-Encoding等;
- 浏览器插件,比如Javascript脚本增加或者修改的Header;同时出于安全性考虑,浏览器对JS控制Header的能力做了限制,
比如Host,Cookie,User-Agent,Accept-Charset,Accept-Encoding,Access-Control-Request-Headers,Access
-Control-Request-Method,Connection,Cookie,Cookie2,Date,DNT,Expect,Keep-Alive,Origin,Refer,TE,
Transfer-Encoding,Upgrade,Vi ,JS是无法干预的。 - 中间代理,如果用户请求要经过一些中间代理(比如运营商或公司网关)中间代理能查看和修改用户全部数据,除非使用了HTTPS。
同理,对于HTTP响应报文也有以下几部分协同生成:httpd守护程序(Nginx等)生成的请求头,CGI(PHP等动态脚本语言)
增加或修改的Header,以及中间代理。
至此,我们对HTTP的报文结构及含义都有了一定的认知,甚至可以自行组装出想要的报文格式。既然拿到了HTTP报文,
下一步就是要建立连接进行HTTP通信啦。

